Dataset 1: Annotation procedure
Institute of Computer Science, Brandenburgische
Technische Universität Cottbus-Senftenberg
Juan-Francisco
Reyes
pacoreyes@protonmail.com
Institute of Computer Science, Brandenburgische
Technische Universität Cottbus-Senftenberg
Juan-Francisco
Reyes
pacoreyes@protonmail.com
### THIS PAGE WILL BE UPDATED PERMANENTLY BASED ON INTERACTIONS ON THE FORUM, RETURN OFTEN
This document delineates the process of cleaning, annotating, and anonymizing a dataset for training a text classification model via Hugging Face technology. The objective is to construct a dataset enabling the model to distinctly identify the linguistic structures of two discourse text categories - monologic and dialogic.
Teams will generate subsets from "Dataset 1," equally split between interviews and speeches. Utilizing an annotation tool, teams will process texts into datapoints for subsequent BERT model fine-tuning.
The project is collaborative, with a collective outcome determining the grade.
Monologic discourses involve a single speaker, while dialogic discourses entail interactions between two or more participants.
Monologic: The prime example of monologic discourse in this project is a speech.
Dialogic: Conversely, interviews exemplify dialogic discourse.
Accurately distinguishing between these text types underpins several computational linguistic endeavors in political discourse analysis, such as speaker attribution in downstream NLP tasks. The correct identification of texts with multiple participants is pivotal.
Teams are to construct a dataset comprising audio/transcribed political discourses, with equal representation of monologic and dialogic examples: 50 speeches and 50 interviews (each involving at least two participants). Dataset 1 aims to set a gold standard for training a deep-learning model to classify these text types. Through manual effort, teams will clean, annotate, and anonymize 300 discourse texts, equally divided into interviews and speeches. Each team member will handle a portion of the texts:
In cases with fewer team members, the dataset will be scaled down to 200 or 100 datapoints for teams of two or one, respectively.
Aligning with the gold standard requirements, the selection criteria we follow to add discourse texts to the dataset include:
Domain: The texts pertain solely to the US political sphere, with American English as the language medium.
Representativity: Selected texts epitomize their respective genres: speeches and interviews, excluding any with elements that may distort the discourse.
Interaction: To prevent model misinterpretation of speaker-audience interactions as dialogic elements, texts with excessive interaction are skipped or adjusted to maintain the discourse integrity. For instance, handling speeches by individuals like Donald Trump, known for engaging audiences with rhetorical questions, necessitates caution.
The annotation process involves using the annotation tool and a shared spreadsheet on Google Drive. Initiate the process by providing the lecturer with the Gmail accounts of all team members to secure Editor access to the spreadsheet.
Within the spreadsheet, locate the list of document IDs allocated to each seminar team. Navigate to the tabs corresponding to your team number (e.g., "monologic_team_5" for Team 5). As all teams share the spreadsheet, exercise consideration towards your peers.
Each tab has six columns: "id," "discourse_type," "politician," "gender," "url," and "note." Initially, only the "id" and "discourse_type" columns are populated; the remaining columns require completion during the annotation task.
id |
discourse_type |
politician |
gender |
url |
notes |
abcnewsgocomPoliticsweektranscriptob |
1 |
The "politician" column denotes the name(s) of the discourse speaker(s) (e.g., "Donald Trump").
"gender" specifies the politician's gender: "M" or "F."
"url" holds the web address of the original document.
"notes" (optional) is reserved for any noteworthy annotation observations, such as a skipped document due to a missing URL or irrelevant content.
Go to the Annotator Tool, logging in with credentials supplied by the lecturer. Select your team from the dropdown menu and launch the tool to begin annotating Dataset 1.
Consider each spreadsheet document as a Dataset 1 datapoint, identified by an ID. Input the document/datapoint ID you intend to annotate.

Upon entry, the editor will launch in a new tab.
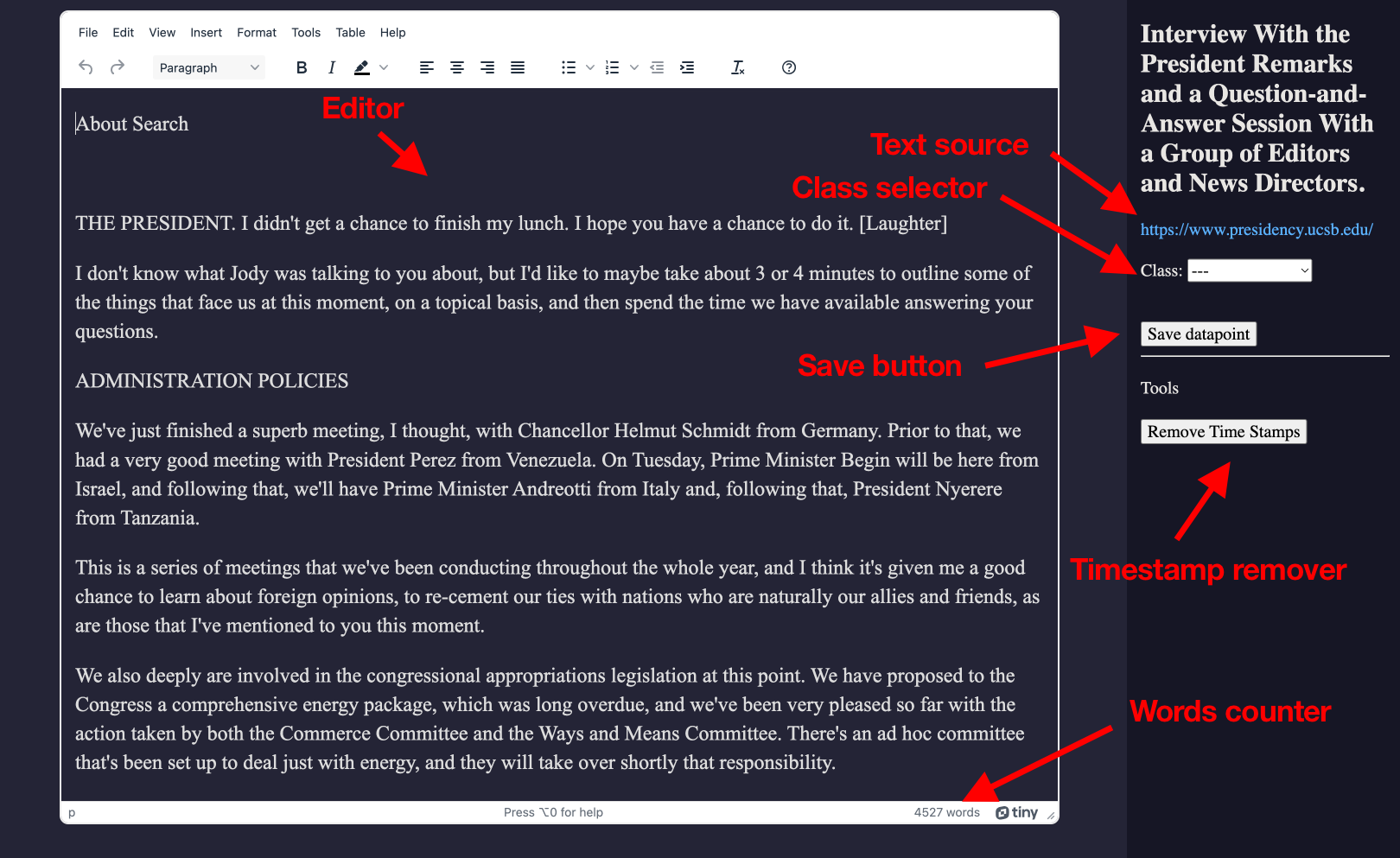
Recognize the following areas and elements:
Editor: The text editing area, accompanied by a word count feature below.
Sidebar: Houses the document title, text source link, class selector, "Save" button, and "Timestamp remover" tool.
The Timestamp remover tool automatically removes the time stamps from transcriptions of some interviews and speeches. For instance: "Donald Trump (00:02):", after applying the remover, results into "Donald Trump:". This tool has different patterns, like "Donald Trump [00:02]:" or "Donald Trump (01:15:02):".
The minimum number of valid datapoints is 450 words. If the document does not have the minimal number of words, the document must be skipped. The minimal number of words is counted after the removal of surrounding text; after text cleaning and processing. Use the word counter to check the text length.
A skipped document does not contribute to the annotated datapoint tally. The annotation goal is 300 datapoints for a trio, 200 for a duo, and 100 for a solo participant. If an excessive number of documents are skipped, and your assigned batch is exhausted, request additional batches from the lecturer.
When skipping a document, refrain from saving it; instead, log the reason in the Google spreadsheet.
Observe the document and confirm it belongs to one of the two classes. Select the class MONOLOGIC or DIALOGIC. If necessary, refer to the source text to understand the nature of the discourse.
Some documents may pose classification challenges. Assess the ease of classifying the document; if it is troublesome, skip it. Occasionally, minor tweaks like omitting brief interactions from another speaker can maintain a document's monologic classification. On the contrary, if a second speaker's involvement is prevalent, consider the document dialogic class or skip or "tweak" it.
Recall that we must include perfect examples of each class in the dataset, and it is allowed to make minor editions to make the class features more salient. It is your task to decide the best strategy to create a good example to train our model.
Hybrid discourses: sometimes, a speech (monologic discourse) ends with a conference (dialogic discourse). If, after removing one of both segments, the remainder of the text is a good example of the chosen class, removing large parts of the original text is valid. Check the word counter to evaluate the removal of large text segments.
By selecting the discourse class, you are annotating the text for the NLP model we will train.
IMPORTANT: A document's initial class assignment in the spreadsheet may be erroneous. For instance, a monologic text might be dialogic. If such discrepancies arise, reclassify the document by moving it to the correct tab. Your meticulous classification of each datapoint is pivotal for dataset quality assurance and is a fundamental aspect of this task.
Surrounding text refers to any content not integral to the primary discourse. The discourse should commence where the main speaker(s) distinctly begin their participation. The onset may include greetings or not, and similarly, it may or may not conclude with farewells. Additionally, surrounding text encompasses introductory remarks by other speakers prior to a speech or interview; such text requires removal. Surrounding text acts as noise and its elimination from the datapoint is essential for a clearer analysis.
In monologic discourses such as speeches, only one participant is involved (refer to Step 4).
Conversely, dialogic discourses like interviews necessitate a minimum of two and a maximum of four participants. Interviews typically comprise at least one INTERVIEWER and one INTERVIEWED. Inclusions of an additional INTERVIEWED and/or INTERVIEWER are permissible. For example, scenarios with two individuals conducting the interview or being interviewed are acceptable. The configuration of two INTERVIEWERS and two INTERVIEWED represents the maximum participant count for interviews. Given the complexity of participant/speaker variance, extra caution is advised when annotating interviews.
The task of anonymization applies solely to speakers engaged in the discourse, where their labels (e.g., "DONALD TRUMP:", "DT:", or "Q.") or cross-references are replaced with placeholders. For example, in an interview featuring Donald Trump as a speaker, his name should be anonymized; however, if he is merely mentioned by another participant, no anonymization is required.
"Named-entities") mentioned in the discourse (e.g., "White House", "N.A.T.O.", or "Germany") should not be anonymized, since they will be anonymized automatically in a further stage.
For this text classification use case, enhancing the saliency of linguistic features for BERT model training is crucial, and the presence of names could mislead the model into classifying texts based on individuals, organizations, or locations. Anonymization strips contextual information, enabling the model to learn from the linguistic structures rather than the contextual content.
The deep-learning model recognizes personal pronouns like "I" ("me, "we", "us", "you", "it", "they", "them", etc.) as (self) references, therefore they should not be anonymized.
Anonymizing monologic text is simpler compared to dialogic text, as the former typically features a single-speaker label, while the latter contains multiple.
Although monologic texts may repetitively display the speaker label, retaining this structure is vital to acquaint the model with this monologic text pattern.
In dialogic texts, careful attention to speaker labels and cross-references is essential. See the applied example below for reference.
Utilize the "Find and Replace" feature (Ctrl + F) in the editor to expedite this step.
As you must have learned in the Hugging Face's NLP Course, deep learning models learn by "seeing" good examples of the classes we want to predict, therefore removing noise in another important step.
Noisy transcribed text are, for instance, applauses, cheers, onomatopoeic expressions, etc., that have been transcribed in the text. Both monologic and dialogic use those patterns, and we must remove them to avoid the model paying attention to them and focus on linguistic structures.
Again, the "Find and Replace" feature is also very useful in this step.
Use the "Save" button to save the datapoint.
For example, view this interview to notice the removal of irrelevant, noisy, or contextual information at the outset, enhancing the clarity of dialogic discourse for the NLP model.
Adopt a unique color for annotating, maintaining consistency throughout to facilitate authorship tracking of each datapoint.
Avoid altering the assigned color. The color scheme has been selected for readability.
Review the applied example tab to understand how datapoints should be grouped by authors based on the designated colors, and consider this before submission.
Ensure politicians' names are written consistently and are easily identifiable, for example, "Donald Trump" instead of "D. Trump." Note that some dialogic texts may feature multiple politicians.
Place all skipped datapoints beneath the annotated texts by the respective annotator (team member) to clearly indicate who skipped a text and the rationale behind the omission.
id |
discourse_type |
politician |
gender |
url |
notes |
abcnewsgocomPoliticsweektranscriptob |
1 |
John Doe |
M |
http://… |
Not rrelevant |
abcnewsgocomPoliticsweektranscrierter |
1 |
John Doe, Jane Doe |
M, F |
http://… |
View the video for guidance on annotating dialogic text. Note that the video doesn't demonstrate the removal of applause, cheers, or speaker-audience interactions; however, these can be eliminated using the "Find and Replace" feature (Ctrl + F).
Open the provided interview and notice the omission of irrelevant, noisy, and contextual information at the outset, enhancing the clarity of dialogic discourse for the NLP model. The interview commences post "With that, we're open to questions," indicating the transition to dialogic discourse. Note the labeling of the interviewer initially as "Q.," later anonymized to [INTERVIEWER]. Additionally, observe the anonymization of "MR. FROMAN" and "MR. STERN" to [INTERVIEWED1] and [INTERVIEWED2], respectively.
Original text:
"Q: On trade, Mike,
would you say this promise to restart Doha in 2010, is that a reflection of
the economic and political realities of the global crisis? Is that something
that the President -- President Obama supports, or was there any effort by
anyone to try to see if it could get on track earlier than that?"
...
Q: Thanks. Mike or
Todd, could you give us some color about the President's role
at the MEF meeting today -- whether he -- where he (inaudible), what actual
effect he had on the final result? And I'll repeat a question that I asked
at the earlier briefing, which was, the President had said he wants the
United States to show leadership on climate change. Did he achieve that
(inaudible)?
MR. FROMAN: I think he certainly
achieved that. I think that there's wide recognition and wide appreciation,
actually, of the role of the United States and the change that the President
has brought in U.S. policy on this issue, which has been more dramatic
perhaps than in any other area.
Anonymized text:
"[INTERVIEWER]: On trade, [INTERVIEWED1],
would you say this promise to restart Doha in 2010, is that a reflection of
the economic and political realities of the global crisis? Is that something
that the President -- President Obama supports, or was there any effort by
anyone to try to see if it could get on track earlier than
that?"
[INTERVIEWER]: Thanks.
[INTERVIEWED1] or [INTERVIEWED2], could you give
us some color about the President's role at the MEF meeting today -- whether
he -- where he (inaudible), what actual effect he had on the final result?
And I'll repeat a question that I asked at the earlier briefing, which was,
the President had said he wants the United States to show leadership on
climate change. Did he achieve that (inaudible)?
[INTERVIEWED1]: I think he certainly achieved that. I
think that there's wide recognition and wide appreciation, actually, of the
role of the United States and the change that the President has brought in
U.S. policy on this issue, which has been more dramatic perhaps than in any
other area.
Recall the GIGO principle: Garbage in, garbage out.
Give quality to your work from the beginning, and don't expect to correct your early mistakes in a later stage without double time and effort.
Recall that once you train your model with your dataset, the returning metrics will grade your work. Again, "garbage in, garbage out".
Don't expect good metrics from a model trained with a low-quality dataset. :(
Concerned about fine-tuning a BERT model with merely 100 datapoints?
If you have this (valid) question in mind, the answer has two parts:
BERT models can only be fed by datapoints with a max number of 512 tokens. At this point, from the Hugging Face's NLP course, you should know what a "token" is.
The sliding-window technique, in a very simplified way, allows us to split large texts into multiple datapoints.
This article explains the issue.
Hence, exclusively opting for shorter texts during annotation is discouraged as it diminishes your model's datapoint count, adversely affecting performance.
There's no necessity to solely target larger texts either – simply adhere to the document ID sequence supplied. Text assignments to teams are randomized, so by following the designated order and concentrating on data-wrangling quality, a balanced approach is achieved.
The objective is to ensure a high degree of agreement among annotators in classifying (into "MONOLOGIC" and "DIALOGIC"), cleaning and anonymizing political discourses. This IAA assessment will aim to verify the consistency and reliability of the annotations, which is crucial for the subsequent analysis involving the BERT model.
Each discourse text will be annotated by at least two different annotators to ensure redundancy. The second annotator –the reviewer– will annotate the agreement assessment based on the following six features:
Add a cross, "x", whenever a discrepancy is found. Leave the cell in blank if no discrepancy was found. Make the correction on the datapoint, and save it.
Follow the structure of the Google Spreadsheet IEFWR 2023/24 - Dataset 1 (IAA). Copy the document and share it with the lecturer (pacoreyesp@gmail.com) when it is complete after following the IAA.
If a discrepancy is found, it should be discussed and resolved with the lecturer. Conduct review meetings with annotators to discuss disagreements and clarify any ambiguities in the guidelines, helping to improve the annotation quality moving forward.
The curator will review and finalize the annotations, establishing a gold-standard corpus.
Recall that each participant must deliver 100 valid datapoints divided into two classes, 50 per class.